
An overview of Airbnb’s Data Framework for faster and more reliable read-heavy workloads.
By: Sivakumar Bhavanari, Krish Chainani, Victor Chen, Yanxi Chen, Xiangmin Liang, Anton Panasenko, Sonia Stan, Peggy Zheng and Amre Shakim
Overview
The evolution of Airbnb and its tech stack calls for a scalable and reliable foundation that simplifies the access and processing of complex data sets. Enter Riverbed, a data framework designed for fast read performance and high availability. In this blog series, we will introduce Riverbed, highlighting its objectives, design, and features.
Why was Riverbed Created
The growth of Airbnb has accelerated the number of databases we operate, the variety of data types they serve, and the addition of data-intensive services accessing these databases, resulting in complex data infrastructure and a Service-Oriented Architecture (SOA) that is difficult to manage.
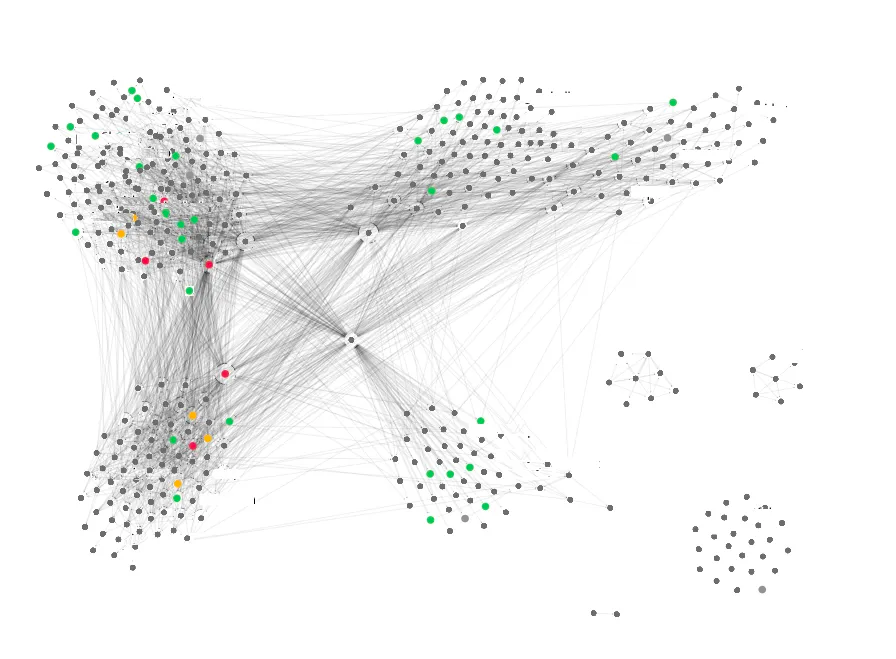
Figure 1. Airbnb SOA dependency graph
We have noticed a specific pattern of queries that involve accessing multiple data sources, have complicated hydration business logic, and involve complex data transformations that are difficult to optimize. Airbnb workloads heavily utilize these queries on the read path, which exacerbates performance issues.
Let’s examine how Airbnb’s payment system faced challenges after transitioning from a monolith to SOA. The payment system at Airbnb is complex and involves accessing multiple data sources while requiring complex business logic to compute fees, transaction dates, currencies, amounts, and total earnings. However, after their SOA migration, the data needed for these calculations became scattered across various services and tables. This made it challenging to provide all the necessary information in a simple and performant manner, particularly for read-heavy requests. To learn more about these and other challenges, we recommend reading this blog post.
One possible solution is to register most frequented queries, pre-compute the denormalized payment data, and provide a table to store the computed results, making them optimized for read-heavy requests. This is known as a materialized view, and is provided as a built-in functionality by many databases.
In an SOA environment where data is distributed across multiple databases, the views we create depend on data from various sources. This technique is widely adopted in industry and usually implemented using a combination of Change-Data-Capture (CDC), stream processing, and a database to persist the final results.
Lambda and Kappa are two real-time data processing architectures. Lambda combines batch and real-time processing for efficient handling of large data volumes, while Kappa focuses solely on streaming processing. Kappa’s simplicity offers better maintainability, but it poses challenges for implementing backfill mechanisms and ensuring data consistency, especially with out-of-order events.
To address these challenges and simplify the construction and management of distributed materialized views, we developed Riverbed. Riverbed is a Lambda-like data framework that abstracts the complexities of maintaining materialized views, enabling faster product iterations. In the following sections, we will discuss Riverbed’s design choices and the tradeoffs made to achieve high performance, reliability, and consistency goals.
Riverbed Design
Overview
At a high level, Riverbed adopts Lambda architecture that consists of an online component for processing real-time event changes and an offline component for filling missing data. Riverbed provides a declarative interface for product engineers to define the queries and implement the business logic for computation using GraphQL for both the online and offline components. Under the hood, the framework efficiently executes the queries, computes the derived data and eventually writes to one or multiple designated sink(s). Riverbed handles the heavy lifting of some common challenges of data intensive systems, such as concurrent writes, versioning, integrations with various infrastructure components at Airbnb, data correctness guarantees, and ultimately enables the product teams to quickly iterate on product features.
Streaming system
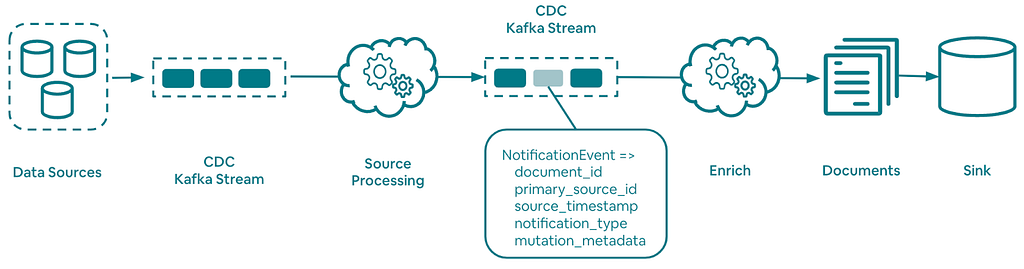
Figure 2. Streaming system
The streaming system’s primary function is to address the incremental view materialization problem that arises when changes are made to system-of-record tables. To achieve this, the system consumes Change-Data-Capture (CDC) events via a Kafka-based system. It converts these events into “notification” triggers, which are associated with specific document IDs in the sink. A “notification” trigger serves as a signal to refresh a particular document. This process occurs in a highly-parallel manner with out-of-order, batched consumers. Within each batch, notification triggers are deduplicated before being written to Kafka.
A second process consumes the earlier produced “notification” triggers. Using a series of joins, data stitching, and executing user-specified operations, the “notifications” are transformed into a document. The resulting document is then drained into the designated sink. Whenever a change occurs on a system-of-record table, the system replaces the affected document with a more up-to-date version, ensuring eventual consistency.
Batch system
There is still a possibility of occasional event loss throughout the pipeline or due to bugs, such as in CDC. Recognizing the need to address these potential inconsistencies, we implemented a batch system that reconciles missing events occurring from online streaming changes. This process helps to identify only the changed data in terms of the materialized view document and provides a mechanism for bootstrapping the materialized view through a backfill. However, reading and processing large volumes of data from online sources may pose performance bottlenecks and potential heterogeneity issues, making direct backfills or reconciliation from these sources infeasible.
To overcome these challenges, Riverbed leverages Apache Spark within its backfilling or reconciliation pipelines, taking advantage of the daily snapshots stored in the offline data warehouse. The framework generates Spark SQL based on GraphQL queries created by clients. Using the data from the warehouse, Riverbed re-uses the same business logic from the streaming system to transform the data and write to sinks.

Figure 3. Batch system
Concurrency/versioning
In any distributed system, concurrent updates can cause race conditions that result in incorrect or inconsistent data. Riverbed avoids race conditions by serializing all changes for a given document using Kafka. Incoming source mutations are first converted to intermediate events only containing the sink document ID and are written to Kafka, then a secondary (notification) process consumes these intermediate events, materializes and writes them to the sink. Because the intermediate Kafka topic is partitioned by the document ID of the event, all documents with the same document ID will be processed serially by the same consumer, avoiding the problem of race conditions from parallel real-time streaming writes altogether.
To solve for parallel writes between real-time streaming and offline jobs, we store a version based on timestamps in the sink. Each sink type is required to only allow writes if the version is greater than or equal to the current version, which solves for race conditions between streaming and batch systems.
Conceptually, Riverbed views each mutation as a hint of a change. The processor always uses data from the source of truth, and hence will produce sink documents in the latest consistent state as of the time of processing. Now processing of events is idempotent and can be done any number of times and in any order.
Results
Riverbed has had a broad impact across Airbnb. It currently processes 2.4B events and writes 350M documents on a daily basis, and powers 50+ materialized views across Airbnb. Riverbed helps power features such as payments, search within messages, review rendering on the listing page, and many other features around co-hosting, itineraries, and internal facing products.
Summary and Next Steps
In conclusion, Riverbed provides a scalable and high-performance data framework that improves the efficiency of read-heavy workloads. Riverbed’s design choices provide a declarative interface for product engineers, efficient execution of queries, and data correctness guarantees. This simplifies the construction and management of distributed materialized views and enables product teams to quickly iterate on features. Using Riverbed for pre-computing views of data has already resulted in significant latency improvements and improved reliability of the flow, ensuring a faster and more reliable experience for Airbnb’s Host and Guest communities.
In future posts, we will explore different aspects of Riverbed in greater detail, including its design considerations, performance optimizations, and future development directions.
Acknowledgments
All of this has been a significant collective effort from the team and any discussion of Read-Optimized Stores would not be complete without acknowledging the invaluable contributions of everyone on the team, both past and present. Big thanks to Will Moss, Krish Chainani, Victor Chen, Sonia Stan, Xiangmin Liang, Siva Bhavanari, Peggy Zheng, Yanxi Chen on the development team; support from Juan Tamayo, Zoran Dimitrijevic, Zheng Liu, Chandramouli Rangarajan and leadership from Amre Shakim, Jessica Tai, Parth Shah, Adam Kocoloski, Abhishek Parmar, Bill Farner and Usman Abbasi. Last but not least, we would like to extend our sincere gratitude to Shylaja Ramachandra, Lauren Mackevich and Tina Nguyen for their invaluable assistance in editing and publishing this post. Their contributions have greatly improved the quality and clarity of the content.
****************
All product names, logos, and brands are property of their respective owners. All company, product and service names used in this website are for identification purposes only. Use of these names, logos, and brands does not imply endorsement.
Riverbed: Optimizing Data Access at Airbnb’s Scale was originally published in The Airbnb Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.